
|
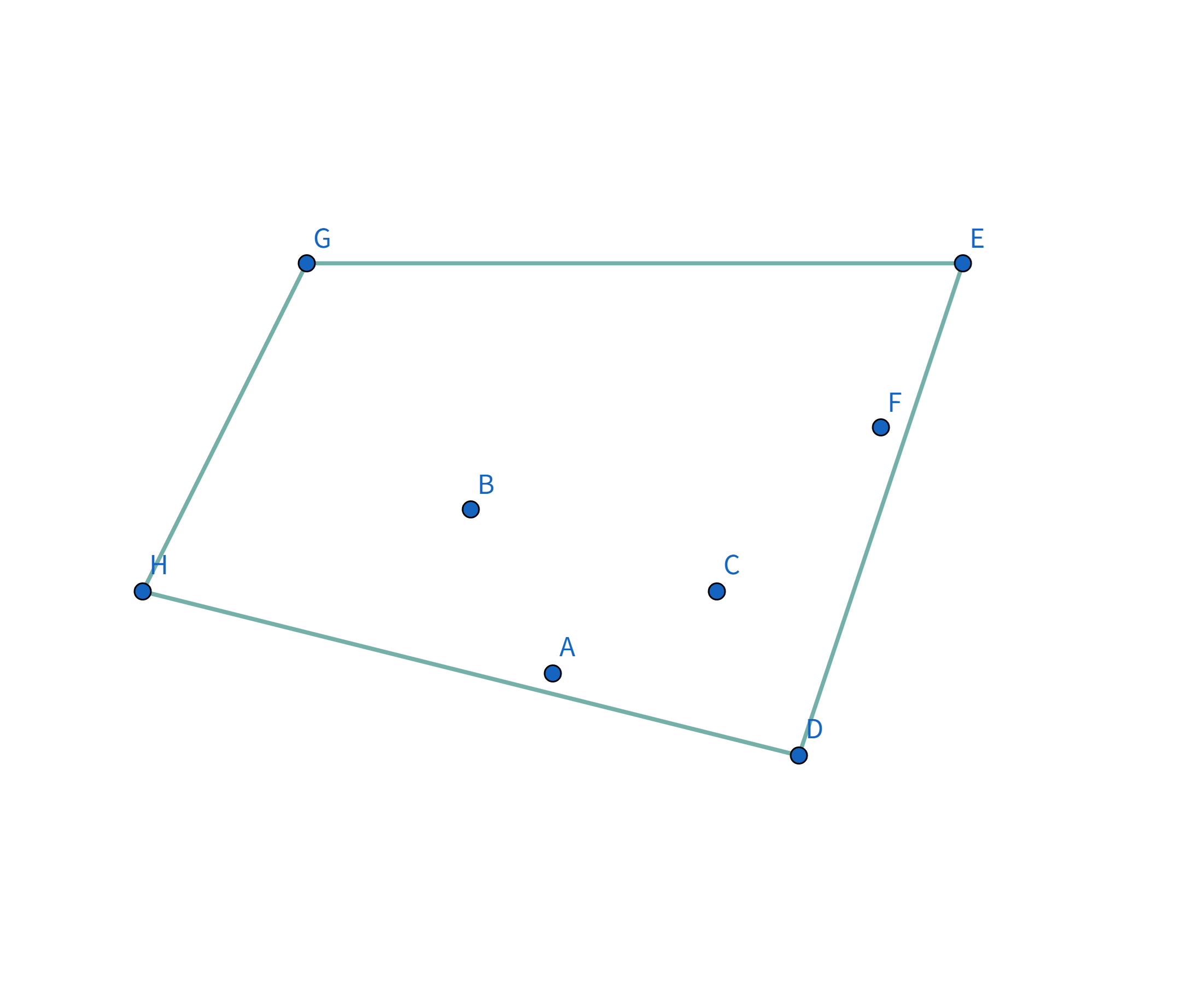
Pro896 圈奶牛 题解896. 圈奶牛 题解题意描述给定有 n 头奶牛,要把这些奶牛用栅栏围起来,栅栏的总长度即为花费,求花费的最小值。 题解例如有这么几头牛:
显然,一个想法是用一个圈把这些牛全部围起来:
但是这样显然不是花费最小的,那我们就让这个椭圆一直缩小,直到和边缘上的点碰触就停止缩小:
这样就是花费最小的啦! 如果再往里缩小的话,花费就会反而变长!
如图,在 $\triangle GHI$ 中,根据三边关系显然有 $GI + IH \gt GH$,所以 $GH$ 就是 $G$ 到 $H$ 花费最小的连接方式。
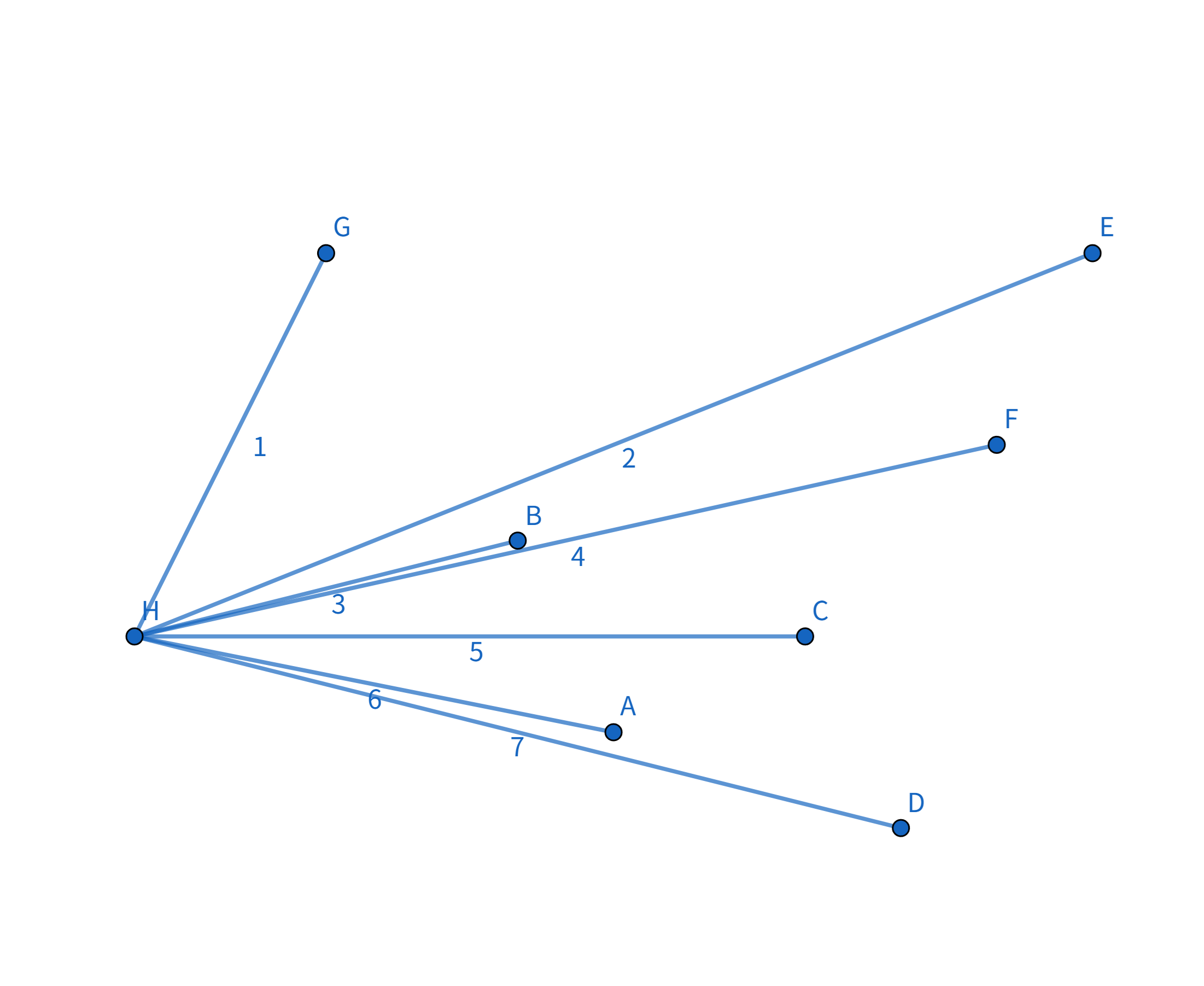
注意到这个连接方式的顶点连线的斜率是递减的 即: $$k_{HG} > k_{GE} > k_{ED} > k_{HD}$$ 那么,我们如何找到这个连接方式呢? 首先找到一个 $x$ 坐标或 $y$ 坐标最大/最小的点,例如图中的点 $H$、点 $G$、点 $E$、点 $D$。 我们以点 $H$ 为例,将这些点排序,按照其他点与点 $H$ 的连线的斜率降序排序(从小到大也可以,只不过实现略有不同):
struct NODE {
double x, y;
} node[MAXN];
double getk(NODE x, NODE y) {
return (x.y - y.y) / (x.x - y.x);
}
int main() {
... // 读入
sort(node + 1, node + n + 1, [](NODE x, NODE y) {
if (x.x != y.x) return x.x < y.x;
return x.y > y.y;
}); // 先进行一个排序,按照 x 坐标为第一关键字升序
// y 坐标为第二关键字降序,也就是要把最左上角的点放到第一个
sort(node + 2, node + n + 1, [](NODE x, NODE y) {
return getk(x, node[1]) > getk(y, node[1]);
});
}
但是 [code](x.x - y.x)[/code] 容易等于零,除数等于零就错误了!那我们就将除法比较改成乘法叭 也就是: $$\frac{a_{1,y} - a_{2,y}}{a_{1,x} - a_{2.x}} \le \frac{b_{1,y} - b_{2,y}}{b_{1,x} - b_{2,x}} \\ \Downarrow \\ (a_{1,y} - a_{2,y})(b_{1,x} - b_{2,x}) \le (b_{1,y} - b_{2,y})(a_{1,x} - a_{2.x})$$
struct NODE {
double x, y;
} node[MAXN];
bool check(NODE a1, NODE a2, NODE b1, NODE b2) {
return (a1.y - a2.y) * (b1.x - b2.x) <= (b1.y - b2.y) * (a1.x - a2.x);
}
double dis(NODE x, NODE y) {
return sqrt(pow(x.x - y.x, 2) + pow(x.y - y.y, 2));
}
int main() {
...
// 找到左上角的点
sort(node + 1, node + n + 1, [](NODE x, NODE y) {
if (x.x != y.x) return x.x < y.x;
return x.y > y.y;
});
// 其余点按照与左上角的点连线的斜率降序排列
sort(node + 2, node + n + 1, [](NODE x, NODE y) {
return !check(x, node[1], y, node[1]);
});
...
}
接下来就是考虑怎么样把 $G,H,D,E$ 四个点选中啦! 我们用一个栈来维护选中的点。 首先点集是这样的:
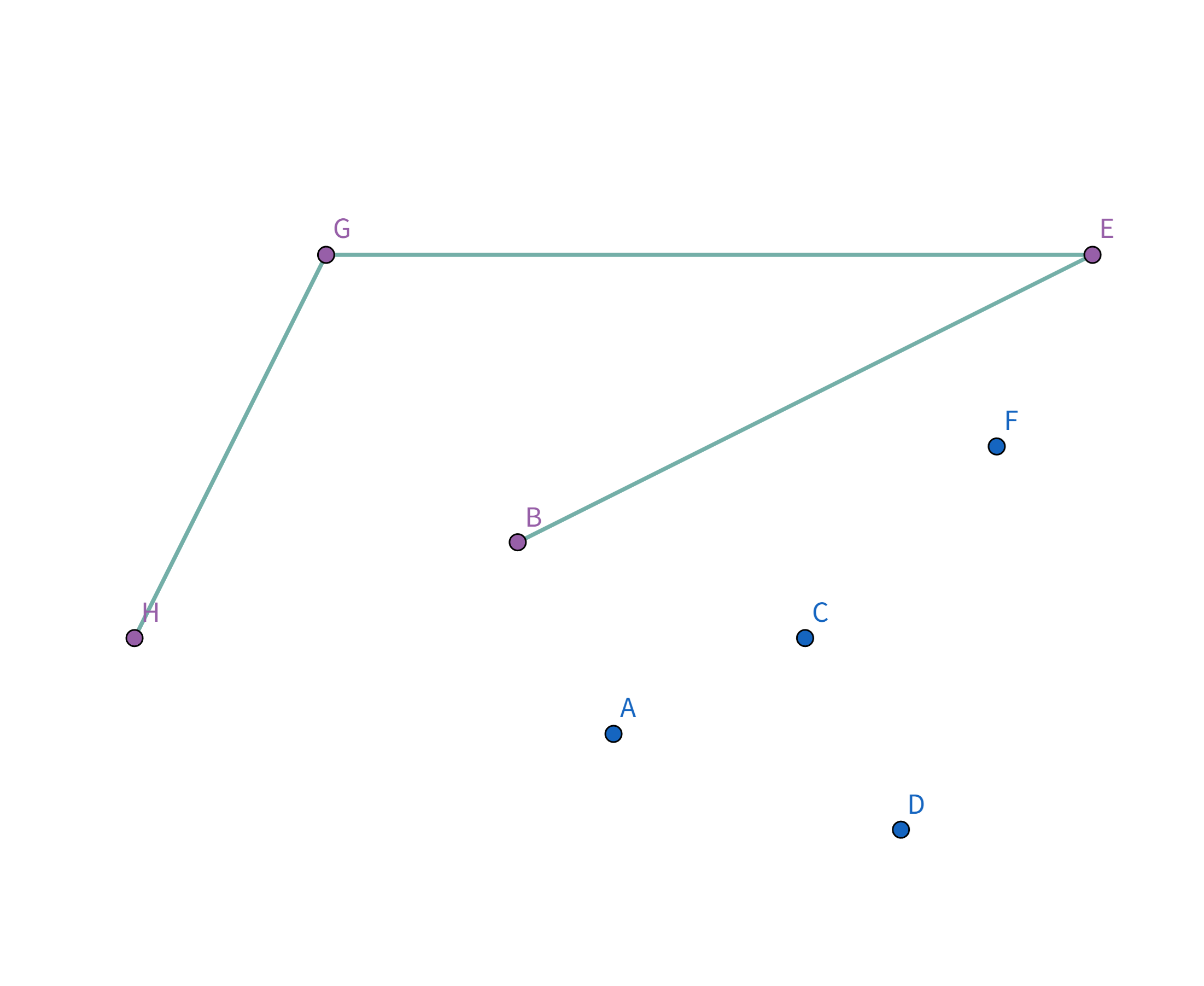
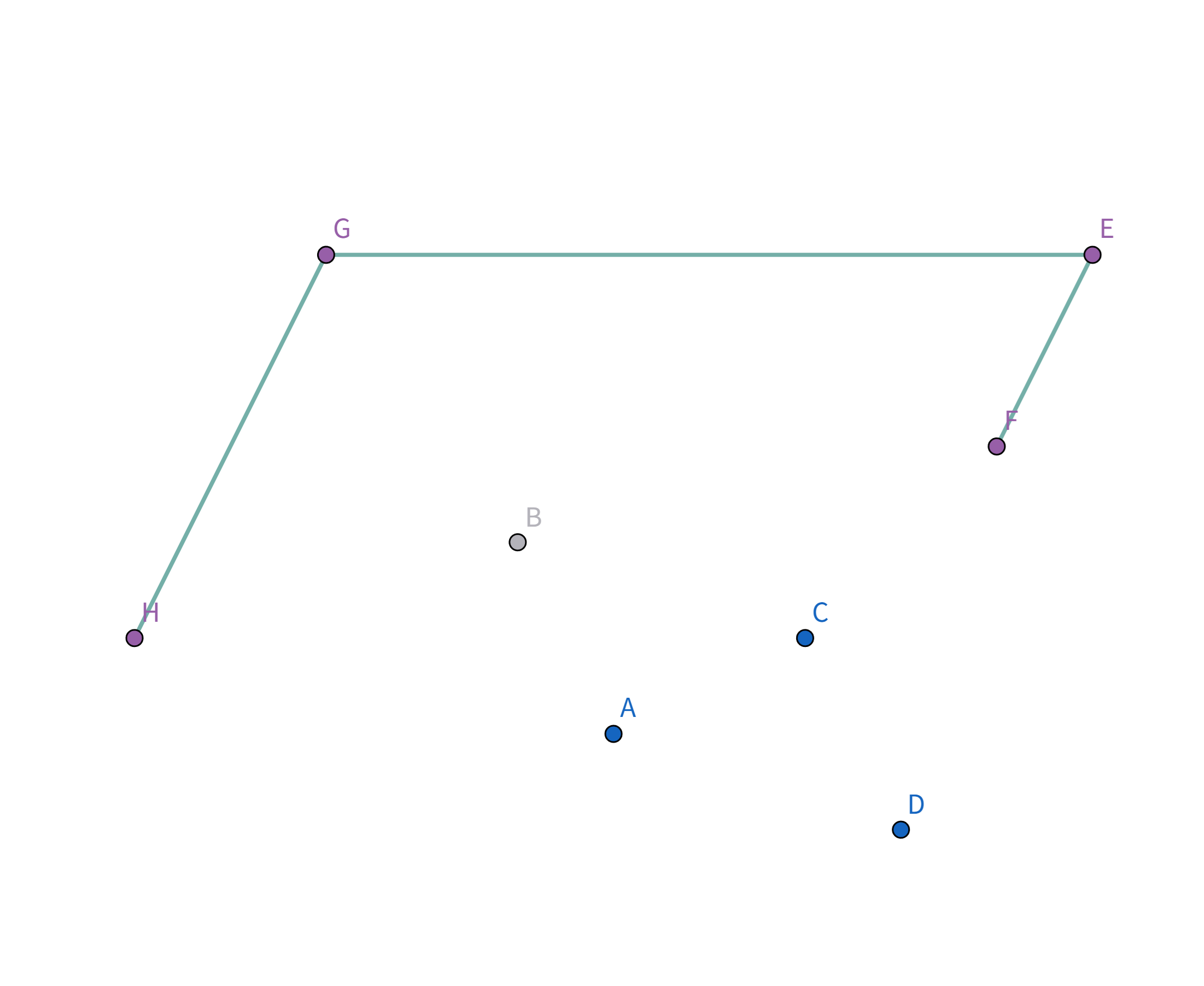
按照排序后的顺序取扫描,首先扫描到点 $H$,此时栈为空,直接把点 $H$ 加入栈:
接着扫描到点 $G$,站内只有一个元素,直接把点 $G$ 加入栈:
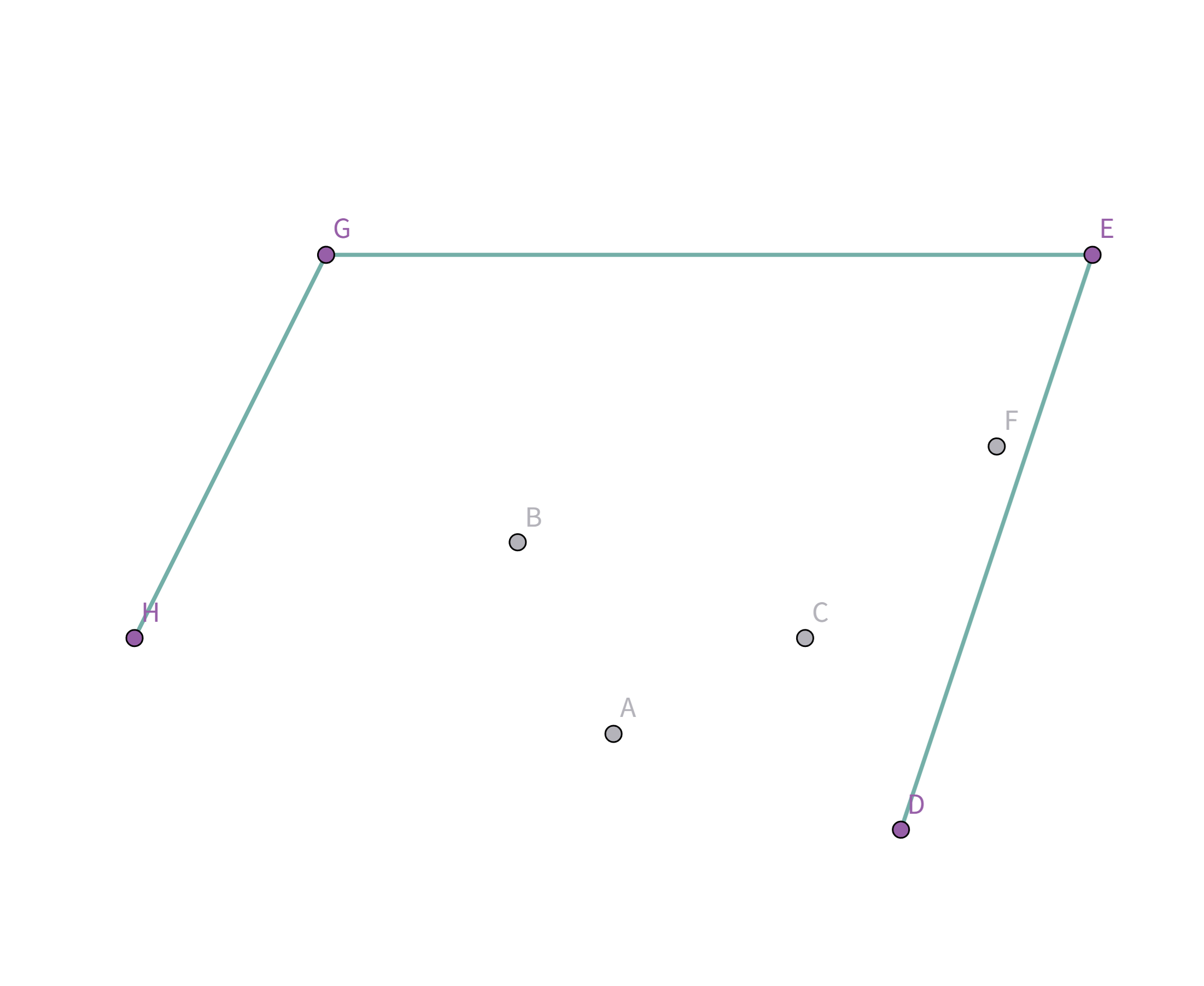
接着扫描到点 $E$,发现其与栈顶的点 $G$ 连线的斜率 与之前的所有连线的斜率 满足递减关系,直接入栈:
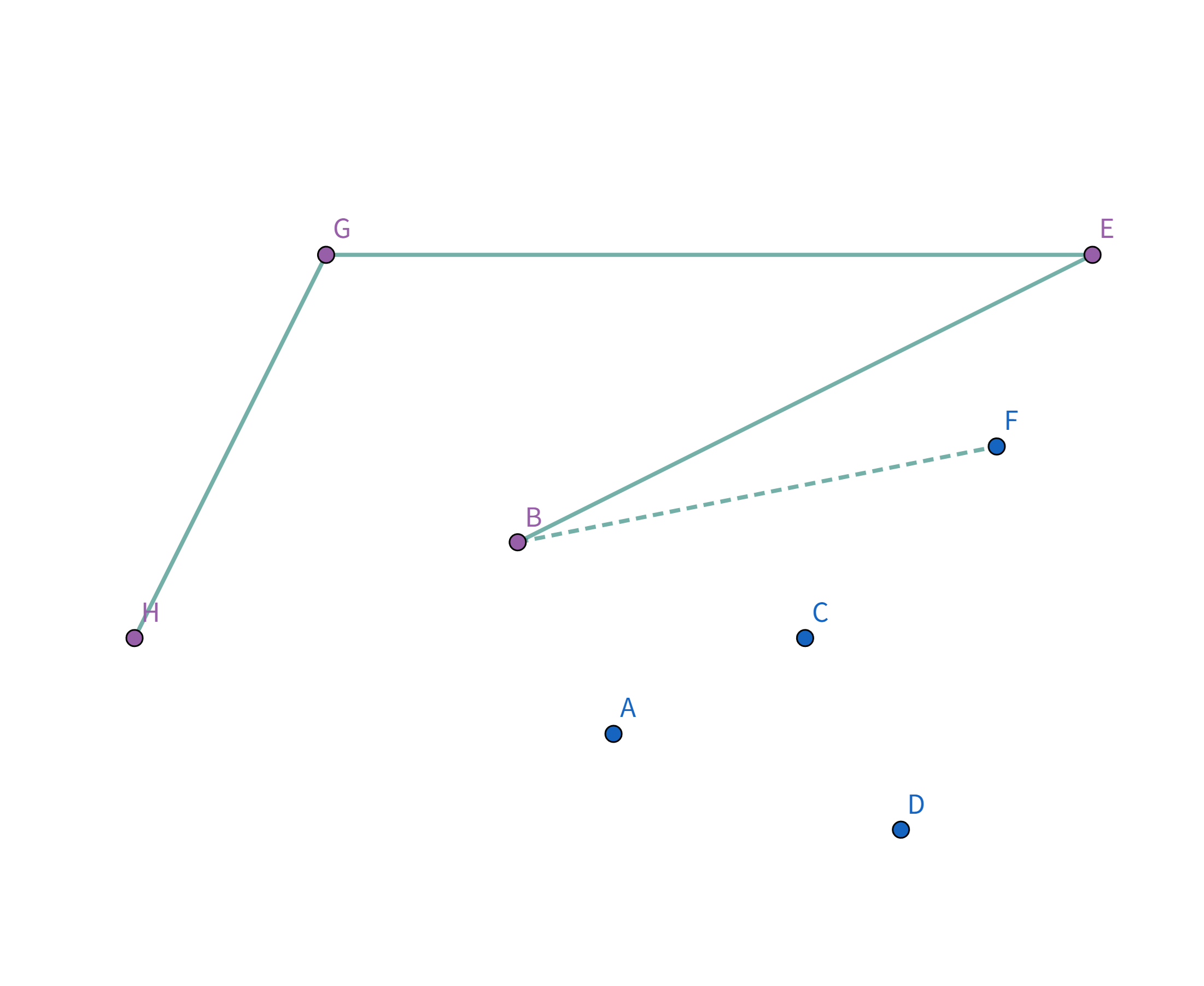
接着扫描到点 $B$,发现其与栈顶的点 $E$ 连线的斜率 与之前的所有连线的斜率 满足递减关系,直接入栈:
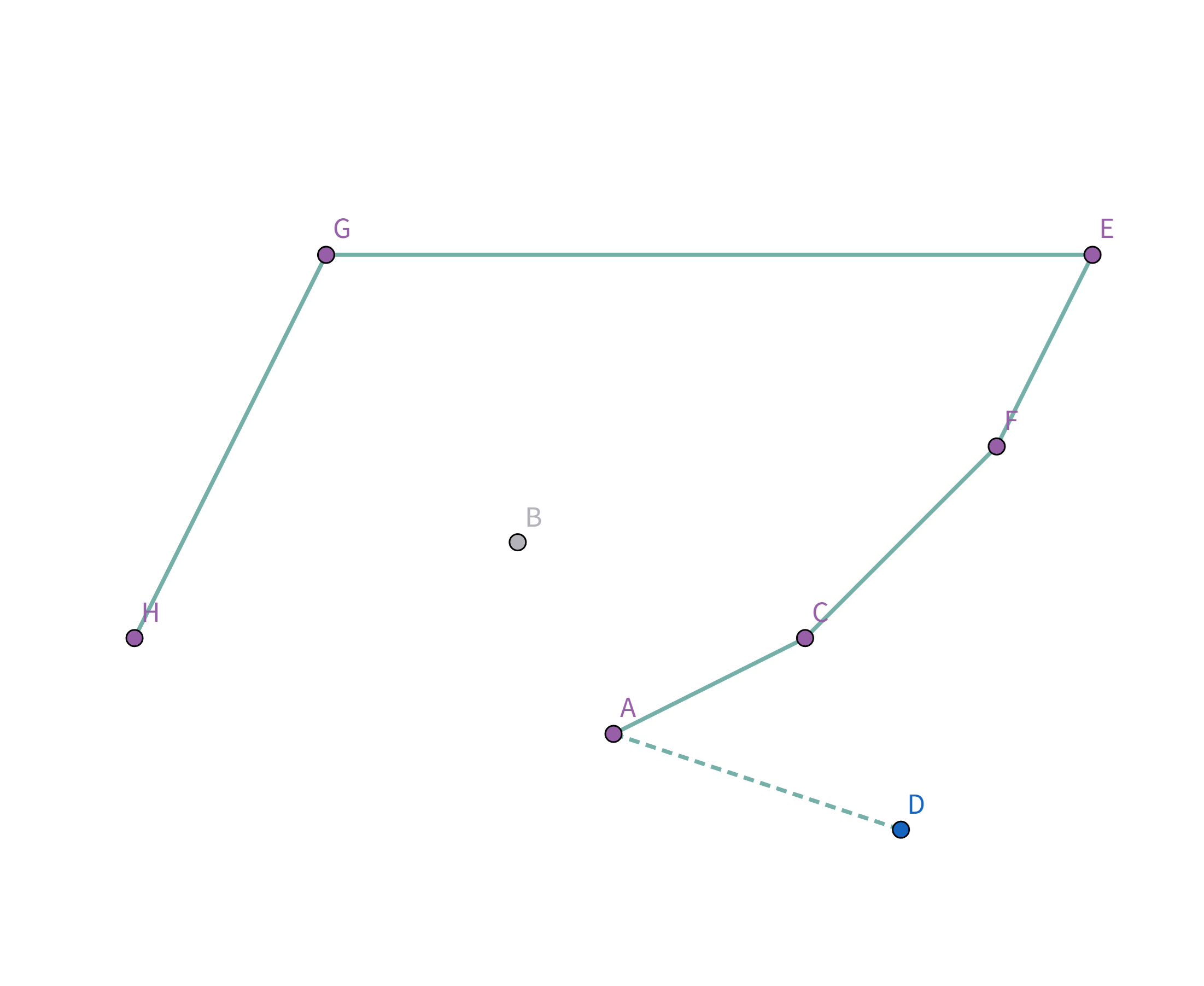
接着扫描到点 $F$!它与栈顶的点 $B$ 的连线斜率比之前大了!
所以把点 $B$ 踢出栈,重复检查点 $F$ 和点 $E$ 的连线是否符合要求。发现其与栈顶的点 $E$ 连线的斜率 与之前的所有连线的斜率 满足递减关系,直接入栈:
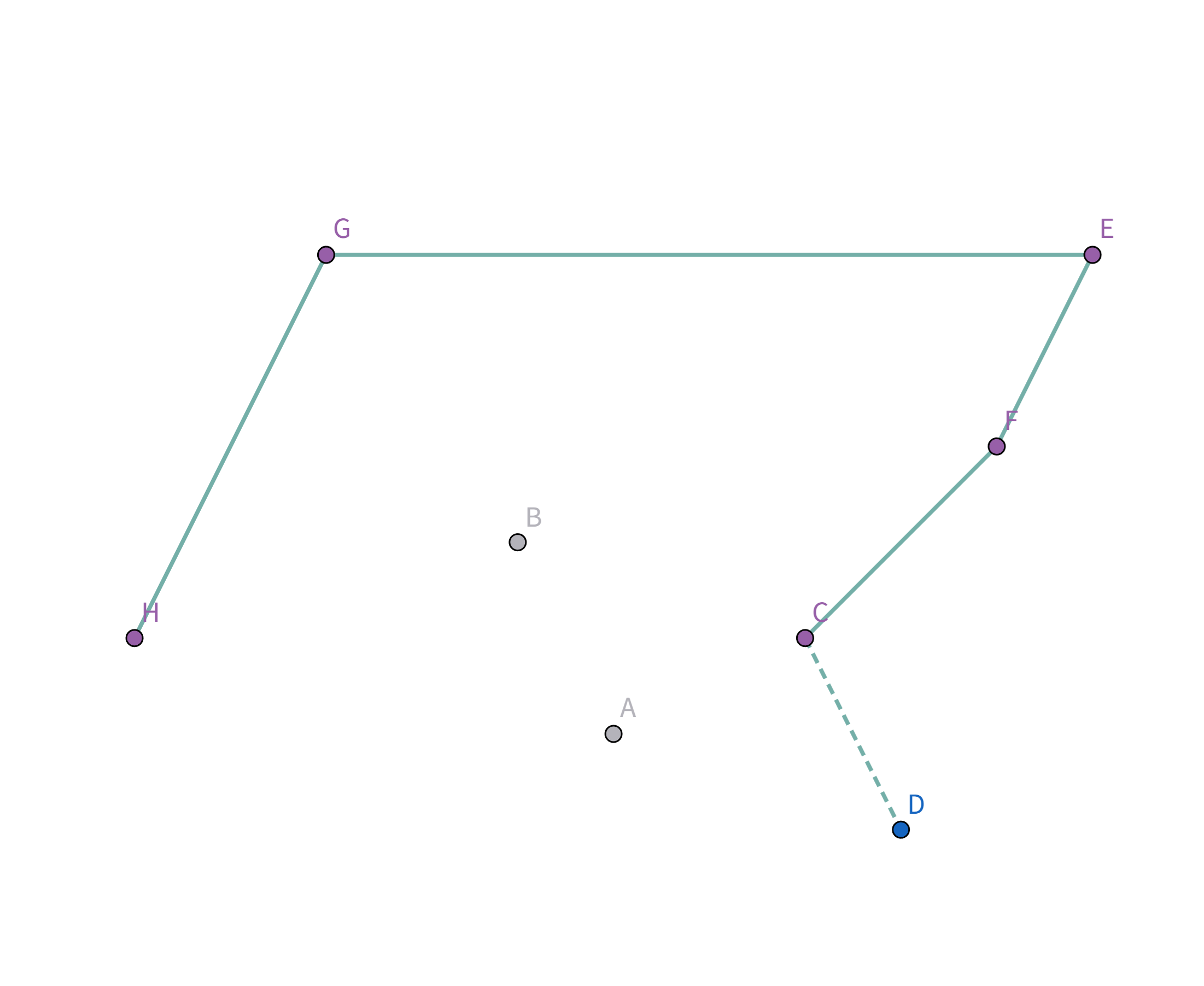
接着扫描到点 $C$,发现其与栈顶的点 $F$ 连线的斜率 与之前的所有连线的斜率 满足递减关系,直接入栈:
接着扫描到点 $A$,发现其与栈顶的点 $C$ 连线的斜率 与之前的所有连线的斜率 满足递减关系,直接入栈:
接着扫描到点 $D$!它与栈顶的点 $A$ 连线斜率比之前大!
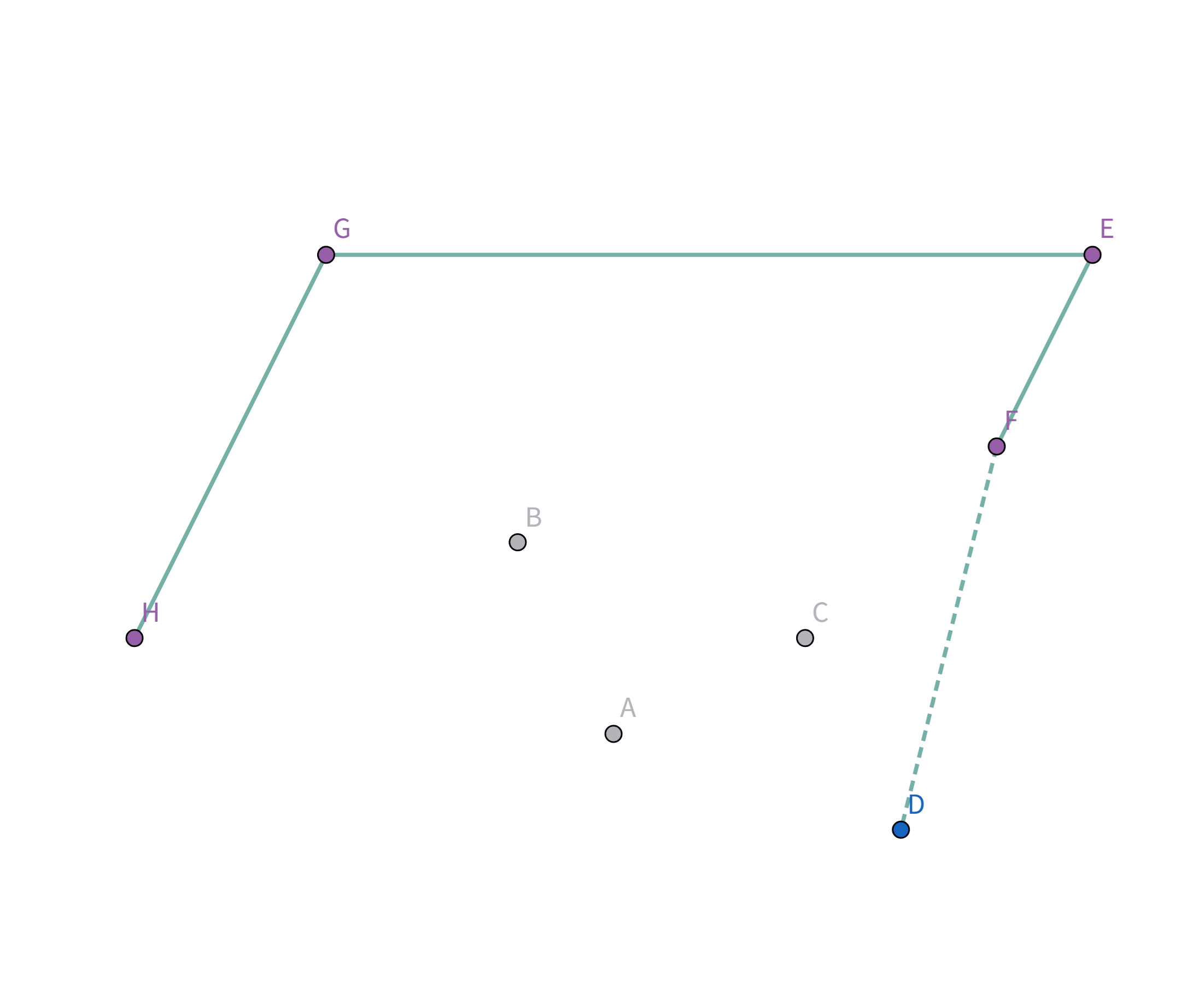
所以把点 $A$ 踢出栈,重复检查点 $D$ 与栈顶点 $C$ 的连线,发现斜率仍然比之前大!
所以把点 $C$ 踢出栈,重复检查点 $D$ 与栈顶点 $F$ 的连线,发现斜率仍然比之前大!
所以把点 $F$ 踢出栈,重复检查点 $D$ 与栈顶点 $E$ 的连线:
终于满足条件了!点 $D$ 与栈顶点 $E$ 连线的斜率 与之前所有连线的斜率 满足递减关系,所以入栈:
所有的点都扫描完啦!所以把最后的点 $D$ 和第一个点 $H$ 连上就好啦!
和前面的图一模一样哦!这个过程模拟就好啦! (其实判断斜率是否满足要求就看这些线段是不是一直在右转就好嘿嘿) NODE sta[MAXN]; int top;
int main() {
...
sta[++top] = node[1];
for (int i = 2; i <= n; ++i) {
while (top > 1 && !check(node[i], sta[top], sta[top], sta[top - 1])) top--;
sta[++top] = node[i];
}
...
}
此时,栈里面的元素就是要求的点集啦! 最后求花费不是难事: double dis(NODE x, NODE y) {
return sqrt(pow(x.x - y.x, 2) + pow(x.y - y.y, 2));
}
double ans;
int main() {
...
for (int i = 2; i <= top; ++i) {
ans += dis(sta[i], sta[i - 1]);
}
ans += dis(sta[top], sta[1]);
...
}
最终代码:
#include <cstdio>
#include <algorithm>
#include <cmath>
using ::std::sort;
using ::std::pow;
using ::std::sqrt;
const int MAXN = 1e5 + 10;
struct NODE {
double x, y;
} node[MAXN];
bool check(NODE a1, NODE a2, NODE b1, NODE b2) {
return (a1.y - a2.y) * (b1.x - b2.x) <= (b1.y - b2.y) * (a1.x - a2.x);
}
double dis(NODE x, NODE y) {
return sqrt(pow(x.x - y.x, 2) + pow(x.y - y.y, 2));
}
int n;
NODE sta[MAXN];
int top;
double ans;
int main() {
freopen("fc.in", "r", stdin);
freopen("fc.out", "w", stdout);
scanf("%d", &n);
for (int i = 1; i <= n; ++i) {
scanf("%lf %lf", &node[i].x, &node[i].y);
}
sort(node + 1, node + n + 1, [](NODE x, NODE y) {
if (x.x != y.x) return x.x < y.x;
return x.y > y.y;
});
sort(node + 2, node + n + 1, [](NODE x, NODE y) {
return !check(x, node[1], y, node[1]);
});
sta[++top] = node[1];
for (int i = 2; i <= n; ++i) {
while (top > 1 && !check(node[i], sta[top], sta[top], sta[top - 1])) top--;
sta[++top] = node[i];
}
for (int i = 2; i <= top; ++i) {
ans += dis(sta[i], sta[i - 1]);
}
ans += dis(sta[top], sta[1]);
printf("%.2lf\n", ans);
return 0;
}
这个代码交到 COGS 上就能过啦!但是是错误的! HACK输入: 18 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 10 0 11 0 12 0 13 0 14 0 15 0 16 0 17 0 18输出: 48.00正确答案: 34.00出现这个问题的原因是所有的点出现在了同一条竖直的线上,数据范围超出了阈值,[code]::std::sort[/code] 函数选择使用快速排序,那么这些点原来按 $y$ 坐标降序的顺序就无法被保证,而这些点传入 [code]check[/code] 函数总是会返回 [code]true[/code],因为 [code]b1.x - b2.x[/code] 和 [code]a1.x - a2.x[/code] 都为 0。最终导致花费计算过多。
解决的办法是排序的时候加上特判。对于在同一条水平的线上的点也用同样的方法就好啦!
sort(node + 2, node + n + 1, [](NODE x, NODE y) {
if (x.x == node[1].x && y.x == node[1].x) return x.y > y.y; // 特判 x 坐标都一样
if (x.y == node[1].y && y.y == node[1].y) return x.x < y.x; // 特判 y 坐标都一样
return !check(x, node[1], y, node[1]);
});
最最终代码:
#include <cstdio>
#include <algorithm>
#include <cmath>
using ::std::sort;
using ::std::pow;
using ::std::sqrt;
const int MAXN = 1e5 + 10;
struct NODE {
double x, y;
} node[MAXN];
bool check(NODE a1, NODE a2, NODE b1, NODE b2) {
return (a1.y - a2.y) * (b1.x - b2.x) <= (b1.y - b2.y) * (a1.x - a2.x);
}
double dis(NODE x, NODE y) {
return sqrt(pow(x.x - y.x, 2) + pow(x.y - y.y, 2));
}
int n;
NODE sta[MAXN];
int top;
double ans;
int main() {
freopen("fc.in", "r", stdin);
freopen("fc.out", "w", stdout);
scanf("%d", &n);
for (int i = 1; i <= n; ++i) {
scanf("%lf %lf", &node[i].x, &node[i].y);
}
sort(node + 1, node + n + 1, [](NODE x, NODE y) {
if (x.x != y.x) return x.x < y.x;
return x.y > y.y;
});
sort(node + 2, node + n + 1, [](NODE x, NODE y) {
if (x.x == node[1].x && y.x == node[1].x) return x.y > y.y;
if (x.y == node[1].y && y.y == node[1].y) return x.x < y.x;
return !check(x, node[1], y, node[1]);
});
sta[++top] = node[1];
for (int i = 2; i <= n; ++i) {
while (top > 1 && !check(node[i], sta[top], sta[top], sta[top - 1])) top--;
sta[++top] = node[i];
}
for (int i = 2; i <= top; ++i) {
ans += dis(sta[i], sta[i - 1]);
}
ans += dis(sta[top], sta[1]);
printf("%.2lf\n", ans);
return 0;
}
时间复杂度:$O(n \log{n} + n)$,瓶颈在排序。
|











 6
6